In de strijd tegen corona leunt men op decennia aan opgebouwde kennis en methoden. Zonder die inspanningen kon men niet zo snel beschikken over mutatie-analyses, sneltesten en nieuwe vaccins. Daarom: zes cruciale ontwikkelingen in de spotlight.
Het bleef lange tijd onopgemerkt, de bijdrage van een Nederlandse cellijn aan productie van coronavaccins. Toch is het de PERC6-cellijn uit het voormalige lab van de Leidse bioloog en tumorviroloog Lex van Eb waarmee farmaceut Janssen tegenwoordig een coronavaccin produceert. En ook de HEK293-cellijn uit Van der Eb’s groep is regelmatig terug te vinden in wetenschappelijke publicaties. Deze cellijnen delen oneindig na transformatie met dna van een adenovirus. Ze groeien gemakkelijk en laten zich opkweken in grote reactoren. Men kan er dus goed eiwitten of vaccins mee produceren. Van der Eb wilde fundamentele mechanismen bestuderen, en hij was niet van plan om het werkpaard van de farmaceutische industrie te ontwerpen. Dat is natuurlijk hoe wetenschap veel vaker werkt: nieuwsgierigheid leidt tot ongeplande vondsten, en ogenschijnlijk triviale publicaties leveren in handen van andere onderzoekers de start van een nieuwe ontwikkeling. Er zijn meer van dit soort voorbeelden, waar de nieuwsgierigheid en volharding van vorige generaties wetenschappers dagelijks helpen in de strijd tegen corona.
Toen in januari 2020 de eerste genoomkaart van sars-cov-2 online beschikbaar kwam, startte een internationale race tegen de klok
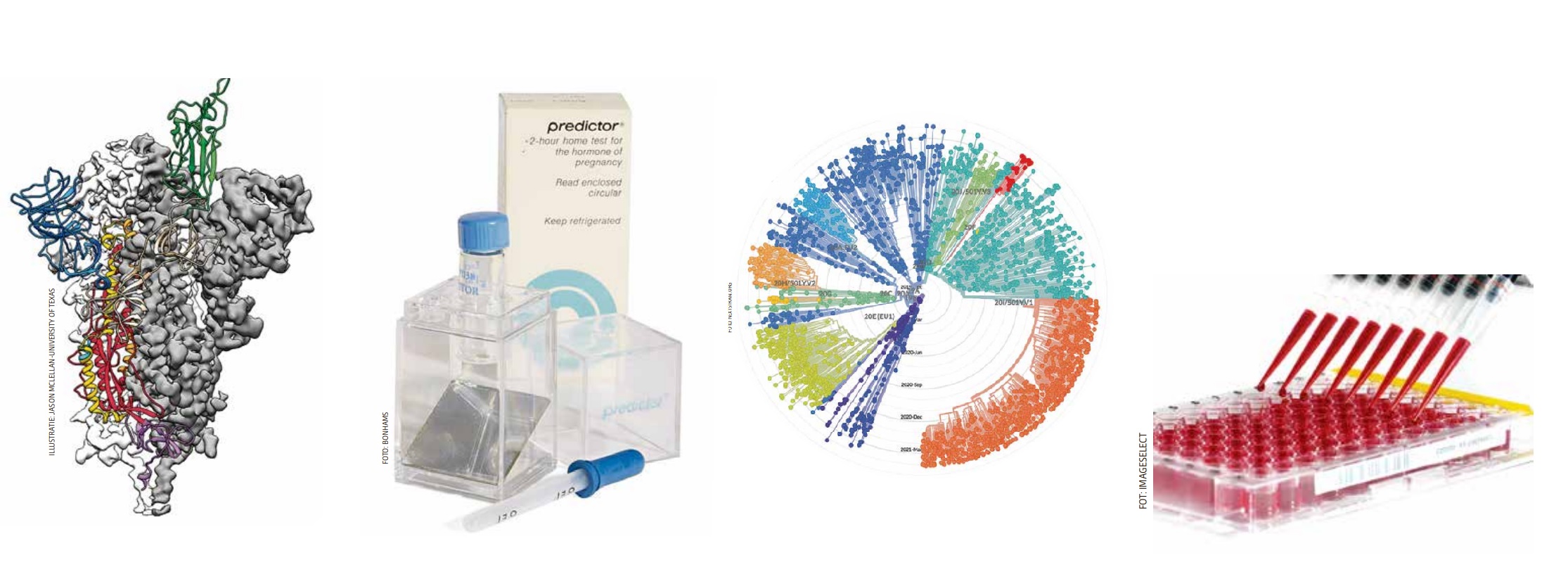
Op cryo-EM gebaseerde voorstelling van de structuur van het sars-cov-2-spike-eiwit met in kleur het domein van receptorbinding.
Cryo-EM (1970)
Toen in januari 2020 de eerste genoomkaart van sarscov-2 online beschikbaar kwam, startte een internationale race tegen de klok. Het 29.811 rna-letters tellende virusgenoom bevat een schat aan informatie. Herkenningssoftware kan snel aanwijzen welke stukken op de kaart voor eiwitten coderen, zoals het spike-eiwit op de virusmantel. Maar het lokaliseren van genen vertelt verder weinig over de exacte moleculaire structuur en hoe deze eiwitten binden aan de menselijke cel. Daarvoor heb je een driedimensionaal model nodig. Zo’n reconstructie begint met het maken van zuiver viruseiwit door de genetische code in een plasmide te bouwen, en een menselijke cellijn of E. coli te transfecteren. Een paar dagen later zit het kweekvocht vol viruseiwit.
Tot dit punt gebruiken wetenschappers de gebruikelijke moleculair biologische technieken, maar de vervolgstappen leunen op oudere onderzoekslijnen. Wie een 3D-model wil maken van een eiwit kan twee routes bewandelen. De ene loopt via röntgendiffractie van eiwitkristallen, maar kristallen groeien duurt vaak maanden. De andere route via elektronenmicroscopische opnamen van individuele eiwitmoleculen is veel sneller. Deze cryo-EM wortelt in de jaren zeventig, maar is pas na veertig jaar ontwikkelwerk van tientallen onderzoeksgroepen een routinetechniek geworden.
Eiwitten verliezen namelijk vocht en hun natuurlijke vorm in een EM-apparaat met hoog-vacuüm bij minus 195 graden Celsius. Bovendien waren de eerste opnames zeer arbeidsintensief en niet zo gedetailleerd. Die hordes zijn inmiddels genomen met een invriesprocedure in vloeibaar ethaan, een nieuwe generatie elektronenmicroscopen en digitale beeldopname. Onderzoekers kunnen tegenwoordig een eiwitoplossing afleveren bij een gespecialiseerde cryo-EM-faciliteit, en de data komt snel retour. Reconstructiesoftware kan vervolgens van vele 2D-opnamen een 3D-model maken. Zodoende had de groep van Jason McLellan van de University of Texas binnen vijf weken de moleculaire structuur van het sars-cov-2-spike-eiwit in handen (Science, 13 maart 2020). Het viruseiwit maakte zijn groep overigens in de Leidse HEK293-cellijn. Kort na McLellans publicatie kwamen ook modellen van andere corona-eiwitten online. De wetenschap kon aan de slag met onderzoek naar virusremmers, mutaties en vaccins.
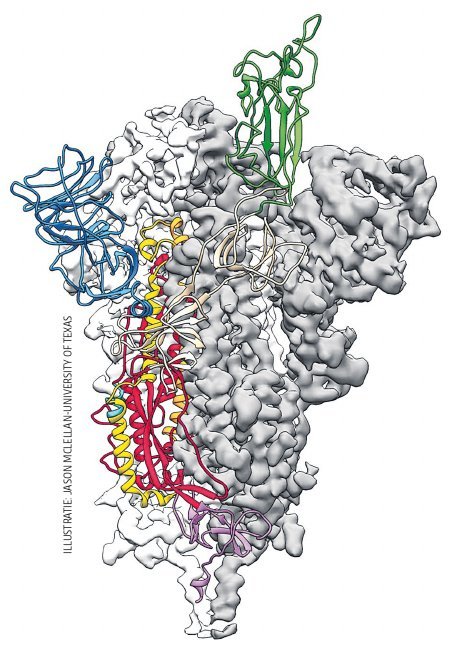
Eerste zwangerschapstest voor consumenten van Chefaro Labs uit Canada in 1971, een voorloper van de latere zwangerschapsthuistesten.
Lateral Flow Assay (1985)
Op weg naar de testsamenleving speelt een ondergewaardeerde technologie een hoofdrol: de lateral flow assay. Druppel wat vloeistof met neusslijm in een gaatje op een plastic cassette, en wacht een paar minuten. Het al dan niet verschijnen van een gekleurd streepje vertelt of iemand een virus onder de leden heeft. Het plastic kleinood van een paar euro belandt daarna in de prullenbak. Men zou vergeten dat binnenin een mini-lab schuilt, het resultaat van zestig jaar onderzoek en ontwikkelwerk, gedekt door honderden patenten op ontwerp, materiaal en fabricage. De sneltest is een voorbeeld van een ontwikkeling zonder opvallende doorbraken of nobelprijzen.
Dat men zo snel over covid-thuistests beschikt, is vooral te danken aan de zwangerschapstest. De diagnostische oerbasis daarvan – latex agglutinatie met antistoffen – stamt uit de jaren vijftig, maar pas eind jaren tachtig kwam de eerste lateral flow zwangerschapsthuistest op de markt. Die lancering stimuleerde nog meer innovatie, waardoor deze testen in de jaren negentig een brede toepassing kregen voor allerlei bepalingen. Er worden met dit soort testen jaarlijks miljarden euro’s omgezet. Logisch dus dat verschillende fabrikanten binnen een paar maanden een covid-19-sneltest op de markt konden brengen.
Zo’n testje is een slimme sandwich van verschillende materialen, geïmpregneerd met droge reagentia. Het druppeltje testvloeistof landt op een poreus laagje dat het testmateriaal conditioneert voor de rest van het assay. Vervolgens stroomt de vloeistof door een stripje met antilichaam met daaraan gekoppeld microscopisch kleine deeltjes goud of latex. Vervolgens vloeit het verder door een membraan waarop een dun streepje antilichaam is aangebracht. Als er virus aanwezig is klonteren de deeltjes daar samen, en wordt een kleurlijntje met het oog zichtbaar. Een controlelijntje vertelt of de test goed is verlopen. Ondertussen hoeft men helemaal niets te doen: capillaire werking mengt en trekt de vloeistof voort.
Next generation sequencing (2000)
Mutaties vormen een belangrijke kopzorg voor virologen en beleidsmakers. In Nederland heeft de Britse variant het inmiddels overgenomen, maar de Braziliaanse P1-variant is al begonnen met een opmars. Surveillance van mutaties is belangrijk, want nieuwe varianten hebben soms een hogere besmettelijkheid, ander ziekteverloop of ze zijn minder gevoelig voor opgebouwde afweer. Bovendien kan men door virusmateriaal te sequensen de oorsprong van een virusuitbraak gedetailleerd in kaart brengen, zoals import via reizigers.
Het omzetten van virus-rna in dna, vermeerdering met PCR (zie ook: ‘Hoe PCR een gouden standaard werd’, Bionieuws 1, 16 januari 2021) en sequensen zijn tegenwoordig routinehandelingen. Daarbij profiteren labs van twintig jaar innovatie, die werd aangezwengeld door het humaan genoomproject (HGP). In de jaren tachtig ontstond het idee om elke base van de mens kaart te brengen, en in 1990 ging het HGP van start met als doel de kaart binnen vijftien jaar af te ronden. Het ging iets vlotter, en in 2001 was het project officieel klaar (Science/Nature, 15/16 februari 2001). Het prijskaartje van 2 miljard dollar is voor moderne begrippen onvoorstelbaar hoog. Het illustreert een stille revolutie: anno 2021 kan men een compleet humaan genoom in een dag in kaart brengen voor rond de 1000 euro.
Het HGP startte met Sanger sequencing met 384 capillairen. Dat vormde een grote sprong voorwaarts, maar deze apparatuur kreeg snellere, efficiëntere opvolgers, zoals 454 Sequencing die inmiddels weer is afgedankt. Het technologie-kerkhof is omvangrijk en het is niet eenvoudig om tweede en derde generatie sequensers precies te scheiden. Op dit moment gebruiken labs van het RIVM en virologen van het Erasmus MC apparatuur zoals llumina MiSeq en Oxford Nanopore MinION. Dat laatste apparaat analyseert dna via porie-technologie. Stuur enkelstrengs dna door een membraan en kleine veranderingen in het voltage verraden of er een A,T, C of G passeert. Doe dat met honderden poriën op een chip, en je kunt heel veel dna tegelijk uitlezen. Zo lukt het altijd wel om uit coronatestmateriaal snel een compleet sars-cov-2-genoom op te pikken.
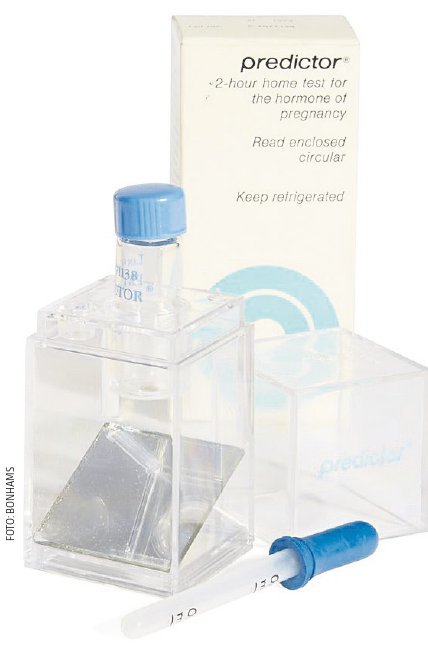
Afbeelding van nextstrain.org die de stamboom van sars-cov-2 laat zien tussen december 2019 en april 2021.
Rna-transfectie (1989)
Dat een van de eerste coronavaccins gebaseerd is op rna-technologie, is mede te danken aan een labmethode waarmee Robert Malone eind jaren tachtig pionierde. In die tijd was het transfecteren van cellen met dna al behoorlijk gevorderd, maar rna gold als instabiel en onhandig. Dit boodschapper-molecuul breekt altijd razendsnel af. Toch kon het inbrengen van rna in cellen veel leren over translatiemechanismen en factoren die de stabiliteit van rna bepalen.
De eenvoudige methode die in 1989 werd gepubliceerd (PNAS, 1 augustus 1989), slaagde erin allerlei praktische obstakels uit de weg te ruimen. Rna verpakt in liposomen bleek prima reproduceerbare resultaten op te leveren. Men kon er bovendien eiwitsynthese in een reeks celsoorten mee onderzoeken, van fruitvlieg via muis tot mens. Een jaar later lieten Malone en collega’s zien dat men rna ook direct in een spier van een muis kan injecteren, waarna de aanmaak van een eiwit weken meetbaar is (Science, 23 maart 1990).
Dat leidde gelijk tot visioenen over het behandelen van ziekten, met rna als alternatief voor gentherapie. Het woord vaccin valt pas een paar jaar later. Het is een voor de hand liggend idee om virale antigenen door het lichaam te laten maken. In 1993 slagen onderzoekers erin om met rna dat voor influenza-eiwit codeert een immuunreactie in muizen op gang te brengen. De rest is dertig jaar geschiedenis.
De eenvoudige methode die in 1989 werd gepubliceerd, slaagde erin allerlei praktische obstakels uit de weg te ruimen
Eiwitten of virussen meten aan de hand van een kleurreactie op een ELISA-plaat is al sinds 1971 standaardtechnologie in diagnostische labs.
ELISA (1971)
De geboorte van het Enzyme Linked Immunosorbent Assay (ELISA) illustreert hoe onderzoekers die een briljante vinding doen, altijd op de schouders staan van collega’s. Want het idee om virussen of eiwitten te meten met behulp van antilichamen en enzymen is stapsgewijs ontstaan. De bouwstenen komen uit fundamenteel immunologisch onderzoek en praktisch gereedschap om antistoffen in het lab te gebruiken.
Er is in die geschiedenis een rol weggelegd voor het onderzoekslab van Organon, waar Anton Schuurs en Bauke van Weemen het enzym-immuno-assay (EIA) ontwikkelden (FEBS Letters, 24 juni 1971). Andere onderzoekers droegen daar gereedschap voor aan met ontwikkeling van chemie waarmee je enzymen aan antilichamen kan koppelen. Zo’n enzym-antilichaam-complex kan een kleurreactie katalyseren, en dat kleursignaal is maat voor de aanwezigheid van de antigenen of antilichamen die men wil meten.
In 1971 voegden de Zweedse onderzoekers Peter Perlmann en Eva Engvall daaraan een innovatie toe (Immunochemistry, september 1971). Hun methode draait om hechting aan het oppervlak van een reageerbuis of microtiterplaat, vandaar ‘Immunosorbent’. Zo kunnen tussendoor verschillende was- en pipetteerstappen worden uitgevoerd, waarbij bijvoorbeeld ongebonden antilichaam wordt verwijderd. ELISA is nog altijd een standaardtechnologie in diagnostische labs, dus ook voor het nauwkeurig bepalen van een eerder doorgemaakte corona-infectie.
Moleculaire fylogenie (1977)
Coronavirussen kan men rangschikken in een moleculaire stamboom op basis van hun rna-sequentie, die onderlinge relaties en evolutionaire afstanden weergeeft. Zo kan men proberen te achterhalen in welke gastheer sars-cov-2 is geëvolueerd, al is dat laatste nog niet gelukt. Dit soort analyses helpen ook om in kaart te brengen hoe varianten van sars-cov-2 als leden van een grote familie aan elkaar verwant zijn.
Dat klinkt allemaal volstrekt logisch, maar toen Carl Woese en George Fox in 1977 hetzelfde deden met ribosomaal rna, werd dat resultaat nauwelijks geaccepteerd (PNAS, 1 november 1977). Woese en Fox waren de eersten die zo’n verwantschapsanalyse maakten op basis van toen schaarse moleculaire data. Hedendaags sequensen bestond niet, en de onderzoekers lazen de lettervolgorde af uit het formaat van radioactieve rna-fragmentjes na inwerking van nucleases.
Als klap op de vuurpijl stelden ze dat er niet twee maar drie rijken te onderscheiden zijn: bacteriën, archaea en eukaryoten. Zowel methode, data als conclusie waren zo buitenaards dat er enige tijd verstreek voordat hun idee gemeengoed werd. Inmiddels is het vergelijken van dna- en rna-volgorden grotendeels geautomatiseerd met computeralgoritmen. Onderzoekers hoeven bij wijze van spreken alleen hun sequensdata te uploaden voor een analyse. Op nextstrain.org/ncov/global kan iedereen die dat wil spelen met de resultaten van deze methodologie. Er zijn zelfs animaties, die het vertakken van de sars-cov-2-boom sinds februari 2020 laten zien.